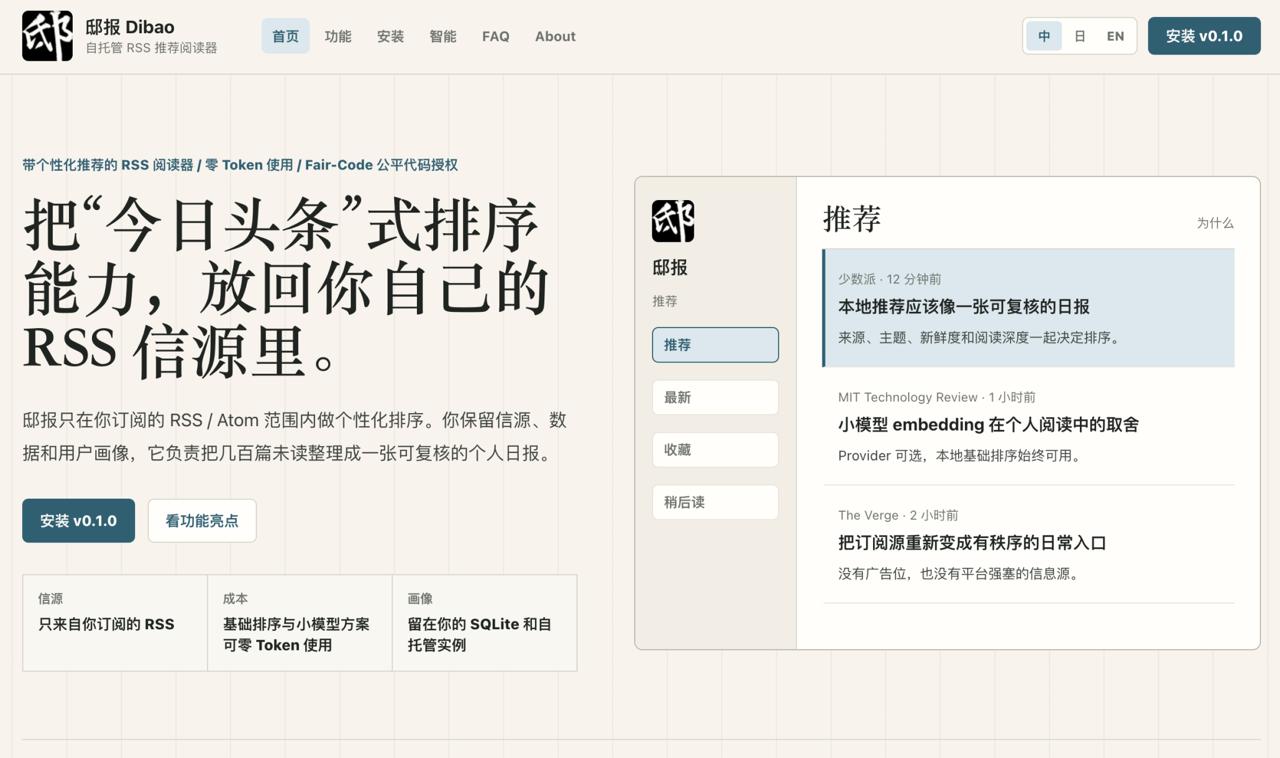
📰 邸报:把推荐算法重新接回 RSS
⭐️ Features:
• 导入 OPML 或 RSS 地址
• 根据阅读行为自动学习偏好
• 支持 Docker Compose 部署
• SQLite 单文件存储
• 无需绑定 LLM API,可接入 embedding 服务或本地模型
RSS 的好处是信息源掌握在自己手里,坏处也是信息源容易古板、陈旧、机械的掌握在自己手里。订阅一多,每天几百篇未读文章堆在收件箱里,阅读很容易逐渐变成一种负担。平台推荐当然省心,但代价是信息分发权也一并交给了平台。邸报在两者之间找一个位置,让信源仍然由用户选择,但排序交给算法完成。导入 OPML、添加 RSS 地址之后,就可以在邸报中像普通阅读器一样浏览、收藏和标记文章。与传统 RSS 阅读器不同之处在于,邸报会根据阅读行为逐渐学习用户的偏好,再对订阅池中的内容重新排序。它不会引入新的信息来源,只是在你已经订阅的文章里,把可能更值得先看的内容浮上来。
这个思路非常合理。现在很多“AI 阅读”产品习惯让大模型直接吞掉整条信息流,逐篇总结、筛选和判断,不仅消耗大量 Token,也容易让阅读变成被模型加工过的二手信息。而邸报选择了另外一条路,通过行为数据、embedding 和排序,已经可以解决大部分需求,每篇推荐还会附带理由,不只是扔给用户一个无法理解的黑盒分数。
部署方面,邸报支持 Docker Compose,可以运行在 NAS、VPS 或本地电脑上。数据保存在 SQLite 文件中,备份基本就是复制粘贴。它不依赖中心化服务,也不强制绑定付费 API。接入硅基流动之类的 embedding provider,或者在本地跑一个小模型,就可以获得不错的推荐效果。
👀 开发者将邸报称作“外部嗅觉器官”,我很喜欢这个描述。RSS 阅读器流行于 2000 年前后,推荐算法在十多年前就已经被大规模验证,但直到今天,两者仍然很少被真正结合起来。邸报目前的完成度和推荐效果都需要更多真实使用来检验。如果你的 RSS 收件箱已经长期处于爆炸状态,又不愿意把阅读完全交给平台算法,邸报很值得试试看。
信息来源:TG频道@NewlearnerChannel